2 Supervised Learning
2.1 About this chapter
- Questions
- How can I find items in data that are like things I already know about?
- Objectives
- Understand labelled data and classification
- Understand training and test data
- Understand K nearest neighbours and Random Forest
- Key Points
- Supervised learning is classifying cases or elements based on examples that we already know
- Good training data is key
- Don’t mix test and training data
In this chapter we’ll take a look at supervised learning tools. It’s called supervised learning because we have a set of data that we have already classified into one or more groups and the algorithms use that as guide and try to fit some other unknown data into the groups we’ve specified, so the classification is supervised in the sense that there are known examples of the groups. Again the input data is usually a data matrix of some features, like measurements or gene expression values.
2.2 Labelled Data
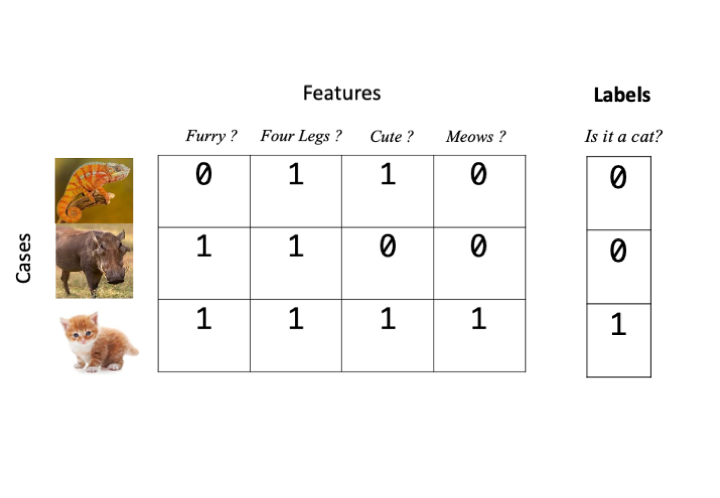
For supervised learning algorithms we need to give examples of our categories. This is called labelling the data. And in most cases we can achieve this just by extending our \(np\) features/cases data matrix by one column and add a label in there, usually as a number. For our animal matrix example that would look like this if we wanted to label our data as a cat or not.
The object for the learning algorithm is then to guess labels for data that we don’t know beforehand. So in our animal matrix example, that looks like this
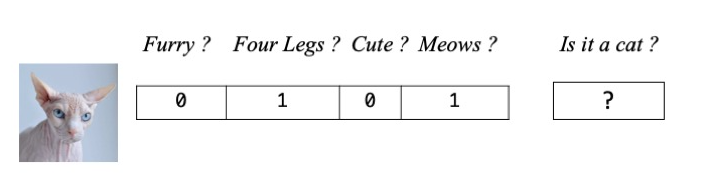
2.3 Training and Testing
2.3.1 The Training Phase
Most supervised learning algorithms have an initial training phase. Training is a part of the procedure where the algorithm creates a model - an internal representation of the data and the associated categories or groups - that it can later use to tell which of our categories a new observation or case belong to. Each type of supervised learner has a different approach to training.
2.3.2 The Testing Phase
Once we have a trained model we must evaluate its accuracy. If we can’t tell how accurate the model is, then we can’t trust it’s predictions and there is not point proceeding. We can test the model on data that we know the labels of but that the model hasn’t seen before. The testing phase is crucial and it is imperative that we don’t use the same data for testing that we used for training, doing so would be like giving a student the answers before the test. The accuracy would be artificially high as they’d already seen the right answers. Once we have a good test of the model done we can use it. Ideally, we’d want the model to give high accuracy, but that can be subjective. For some applications we might need 99% or greater accuracy, in others just getting an answer better than random would do.
2.4 Measuring accuracy
Measuring accuracy of a model in the testing phase is less straightforward than we might first think We might assume that all we have to do is count the number of test cases that we got correct, but that is only one quarter of the story at best!. In fact, for a binary classification (a model that knows only two groups, e.g in our animal example a model that can say whether it thinks something is or isn’t a cat) there are two ways to be right and two ways to be wrong and we must calculate as many of these we can in order to get a good accuracy estimate. For a model with more than two groups or for models trying to predict a quantity rather than a group the question is more complicated and we’ll look at those later.
2.4.1 Two ways to be right: True Positives and True Negatives
The two ways to be right are to get a correct positive classification - a True Positive and a correct negative classification - a True Negative. These are easier to understand graphically. In the figure below we have a set of trained model generated answers and their true classes.

A True Positive occurs when the model classifies a case positively (is a cat) and is correct, similarly a True Negative occurs when the model classifies a case negatively (is not a cat) and is correct.
2.4.2 Two ways to be wrong: False Postive and False Negatives
The two ways to be wrong are False Positive and false negative classifications False Positives and False Negatives. A False Positive occurs when the model classifies a non-cat as a cat and a False Negative occurs when the model classifies a cat as not a cat.

2.4.3 Sensitivity and Specificity
For a given set of test data for which we know the true labels, we run the model and get it’s classifications. We can count up the True/False Positive/Negatives and calculate two quantities Sensitivity and Specificity. Sensitivity tells us roughly what proportion of True Positives we got, given the errors and Specificity tells how few wrong calls we made. The two measures are therefore complementary and are used together to get a picture of how well the model performs. A good model is high in both. The quantities are calculated as follows
\(Sensitivity = \frac{TP}{TP+FN}\) \(Specificity = \frac{TN}{TN+FP}\)
2.4.4 Other measures of accuracy
There are in fact, many other measures of accuracy in use beyond sensitivity and specificity. These include things called \(F\) scores, precision and recall, FDRs and (confusingly) one actually called accuracy. It’s important to know that they are all a bit different and give different measures but they all try to capture the ‘rightness’ or ‘accuracy’ of our classifiers. As we try out different tools we will see other measures.
2.5 \(k\)-Nearest Neighbours
The \(k\)-Nearest Neighbour algorithm is a multi-class capable classification algorithm. Like the unsupervised methods this relies on distance measures between cases/elements and tries to apply a class to an unknown element by looking at the number of nearest neighbours classes. Roughly, the unknown case gets the class of the majority of the \(k\) nearest neighbours. We can see an example in the figure below
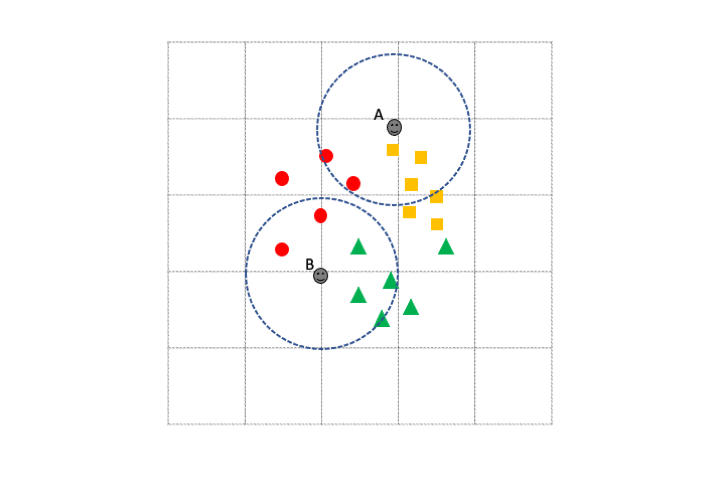
If we set \(k\) to be 5 then Unknown case A has 3 orange squares and 2 red circles in its 5 nearest neighbours, so unknown case A would be classified as an orange square. Similarly, unknown case B has more green triangles in its \(k\) nearest neighbours so it gets classified as a green triangle. Note how the known class labels are crucial in putting the unknown cases into classes. This approach only works because we have some known examples. Also note how much harder the algorithm would find the task if there were too few examples of each class. For this and many other types of supervised learning algorithm, the more training data we have, the better.
2.5.1 Training and evaluating \(k\)NN
Let’s run through using the algorithm with the data below. The first phase is training and evaluation. There are 3 sets we will use, a training set of 55 points, which is labelled in a separate vector (train_data and train_labels), a test set of 20 points that is labelled (test_data and test_labels) and an unlabelled, unknown data set of 75 points that we wish to label using \(k\) Nearest Neighbours.
dplyr::glimpse(train_data)Rows: 55
Columns: 4
$ measure1 <dbl> 6.7, 5.4, 6.4, 5.0, 5.3, 5.4, 5.4, 5.7, 6.0, 5.1, 6.0, 5.8, 4…
$ measure2 <dbl> 3.1, 3.4, 3.2, 3.2, 3.7, 3.9, 3.0, 4.4, 2.9, 3.8, 2.2, 2.6, 3…
$ measure3 <dbl> 5.6, 1.7, 5.3, 1.2, 1.5, 1.7, 4.5, 1.5, 4.5, 1.9, 4.0, 4.0, 1…
$ measure4 <dbl> 2.4, 0.2, 2.3, 0.2, 0.2, 0.4, 1.5, 0.4, 1.5, 0.4, 1.0, 1.2, 0…train_labels [1] C A C A A A B A B A B B A A B C C A A B A B B C A A A A C C B C B A B C C B
[39] A A B C B C C A C B A A A B B C B
Levels: A B Cdplyr::glimpse(test_data)Rows: 20
Columns: 4
$ measure1 <dbl> 5.6, 6.7, 6.3, 6.3, 5.0, 7.2, 6.2, 6.7, 4.6, 5.1, 6.0, 6.7, 7…
$ measure2 <dbl> 3.0, 2.5, 3.3, 2.7, 2.3, 3.6, 2.2, 3.1, 3.4, 3.8, 2.2, 3.3, 3…
$ measure3 <dbl> 4.1, 5.8, 6.0, 4.9, 3.3, 6.1, 4.5, 4.7, 1.4, 1.6, 5.0, 5.7, 6…
$ measure4 <dbl> 1.3, 1.8, 2.5, 1.8, 1.0, 2.5, 1.5, 1.5, 0.3, 0.2, 1.5, 2.1, 2…test_labels [1] B C C C B C B B A A C C C A A B A A B A
Levels: A B Cdplyr::glimpse(unknown_data)Rows: 75
Columns: 4
$ measure1 <dbl> 5.6, 5.0, 6.3, 6.1, 5.8, 5.5, 5.1, 5.1, 7.2, 5.0, 4.7, 7.7, 5…
$ measure2 <dbl> 2.9, 3.6, 2.8, 2.8, 2.7, 2.6, 3.8, 3.7, 3.0, 3.0, 3.2, 2.8, 3…
$ measure3 <dbl> 3.6, 1.4, 5.1, 4.7, 5.1, 4.4, 1.5, 1.5, 5.8, 1.6, 1.6, 6.7, 1…
$ measure4 <dbl> 1.3, 0.2, 1.5, 1.2, 1.9, 1.2, 0.3, 0.4, 1.6, 0.2, 0.2, 2.0, 0…The first step is to train and test a model. As we are going to go through the process twice (one evaluating, one with unknown data), we must remember to control the random element of the algorithm. set.seed() with a consistent argument (123) puts the random number generator back to the same place each time allowing reproducibility.
The knn() function is in the class package so we load that and pass it the train_data to learn from and the known test_data to predict groups on. The cl parameter gets the vector of train_labels. Finally the \(k\) nearest neighbours is passed as k, here 9.
set.seed(123)
library(class)
test_set_predictions <- knn(train_data, test=test_data, cl = train_labels, k=9)
test_set_predictions [1] B C C C B C B B A A B C C A A B A A B A
Levels: A B CAs we can see, the predictions are returned as vector whose elements correspond to the rows of test_data. We can check the accuracy of the predictions by comparing the predictions with the known labels. The caret package function confusionMatrix() returns an object with lots of useful information.
library(caret)
confusionMatrix(test_set_predictions, test_labels)Confusion Matrix and Statistics
Reference
Prediction A B C
A 7 0 0
B 0 6 1
C 0 0 6
Overall Statistics
Accuracy : 0.95
95% CI : (0.7513, 0.9987)
No Information Rate : 0.35
P-Value [Acc > NIR] : 2.903e-08
Kappa : 0.9251
Mcnemar's Test P-Value : NA
Statistics by Class:
Class: A Class: B Class: C
Sensitivity 1.00 1.0000 0.8571
Specificity 1.00 0.9286 1.0000
Pos Pred Value 1.00 0.8571 1.0000
Neg Pred Value 1.00 1.0000 0.9286
Prevalence 0.35 0.3000 0.3500
Detection Rate 0.35 0.3000 0.3000
Detection Prevalence 0.35 0.3500 0.3000
Balanced Accuracy 1.00 0.9643 0.9286At the top of the output, the confusion matrix shows how ‘mixed’ up the model got. Read it down the columns, so that for the 7 real group A the algorithm predicted 7 A, 0 B and 0 C; for the 6 real group B the algorithm predicted 0 A, 6 B and 0 C and for the 7 real group C the predictions were 0 A, 1 B and 6 C, so a C was misclassified as a B. This error rate and pattern is reflected in the overall accuracy, stated as 95 % and the more useful per group Sensitivity and Specificity, the lower Specificity for group B is due to the C miscalled as a B (so a false positive B). The same error causes the lower Sensitivity for group C.
2.5.2 Using a trained model
Now that we have evaluated the model and know how accurate it is - and that it is accurate enough to be useful, we can run on our unknown data. This is virtually identical to before, replacing the test_data with the unknown_data. We must remember to reset the random number generator again, and we can go ahead and add the predictions straight to the data frame if we wish. We now have predicted groups for the unknown data and an estimate of the accuracy of our predictions.
set.seed(123)
unknown_predictions <- knn(train_data, test=unknown_data, cl = train_labels, k=9)
unknown_data$predicted_group <- unknown_predictions
dplyr::glimpse(unknown_data)Rows: 75
Columns: 5
$ measure1 <dbl> 5.6, 5.0, 6.3, 6.1, 5.8, 5.5, 5.1, 5.1, 7.2, 5.0, 4.7,…
$ measure2 <dbl> 2.9, 3.6, 2.8, 2.8, 2.7, 2.6, 3.8, 3.7, 3.0, 3.0, 3.2,…
$ measure3 <dbl> 3.6, 1.4, 5.1, 4.7, 5.1, 4.4, 1.5, 1.5, 5.8, 1.6, 1.6,…
$ measure4 <dbl> 1.3, 0.2, 1.5, 1.2, 1.9, 1.2, 0.3, 0.4, 1.6, 0.2, 0.2,…
$ predicted_group <fct> B, A, C, B, C, B, A, A, C, A, A, C, A, C, B, B, C, A, …2.6 Random Forest
Random Forest is another supervised learning algorithm that is based on ensembles of decision trees. A decision tree is a model that resembles a question flowchart that has a ‘question’ at each branch point and continues until enough have been ‘asked’ to differentiate the item in hand. Here is one potential decision tree for the animal classification we’ve been using.
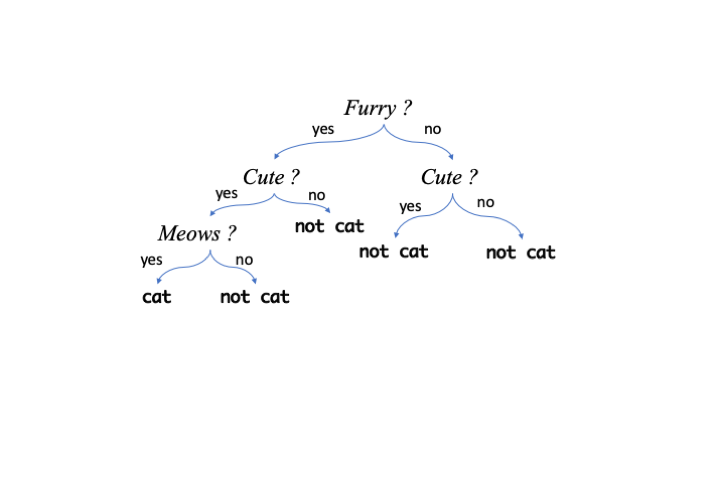
In a Random Forest classifier trees are made using the training data and the ones that are best at classifying the data are retained. There are a whole set of possible good trees so the ensemble of trees is used, hence Random Forest. The many trees make up one model that are used with unseen data.
2.6.1 Building a Random Forest Model
We use the randomForest package to do this, and we will use the training and test data as we did with \(k\) nearest neighbours above, for random forest, the labels are specified in the data, so we don’t have a separate label vector and must now add them on to the training and test data. Let’s do that first
train_data$group <- train_labels
dplyr::glimpse(train_data)Rows: 55
Columns: 5
$ measure1 <dbl> 6.7, 5.4, 6.4, 5.0, 5.3, 5.4, 5.4, 5.7, 6.0, 5.1, 6.0, 5.8, 4…
$ measure2 <dbl> 3.1, 3.4, 3.2, 3.2, 3.7, 3.9, 3.0, 4.4, 2.9, 3.8, 2.2, 2.6, 3…
$ measure3 <dbl> 5.6, 1.7, 5.3, 1.2, 1.5, 1.7, 4.5, 1.5, 4.5, 1.9, 4.0, 4.0, 1…
$ measure4 <dbl> 2.4, 0.2, 2.3, 0.2, 0.2, 0.4, 1.5, 0.4, 1.5, 0.4, 1.0, 1.2, 0…
$ group <fct> C, A, C, A, A, A, B, A, B, A, B, B, A, A, B, C, C, A, A, B, A…We can now build the model with the randomForest() function. The setup uses R’s formula based syntax, so is very similar to that we used for linear models. The group is to be predicted based on . which means all other columns in the data train_data. The model variable holds the trained model
library(randomForest)
model <- randomForest(group ~ ., data = train_data, mtry=2)2.6.2 Testing a Random Forest model
With the model built we can use the generic predict() function to get the model to predict groups for the unlabelled test_data then compare it to the real groups with confusionMatrix(). Setting the value of type to class tells the predict() we want group classifications
test_set_predictions <- predict(model, test_data, type="class")
confusionMatrix(test_set_predictions, test_labels)Confusion Matrix and Statistics
Reference
Prediction A B C
A 7 0 0
B 0 6 1
C 0 0 6
Overall Statistics
Accuracy : 0.95
95% CI : (0.7513, 0.9987)
No Information Rate : 0.35
P-Value [Acc > NIR] : 2.903e-08
Kappa : 0.9251
Mcnemar's Test P-Value : NA
Statistics by Class:
Class: A Class: B Class: C
Sensitivity 1.00 1.0000 0.8571
Specificity 1.00 0.9286 1.0000
Pos Pred Value 1.00 0.8571 1.0000
Neg Pred Value 1.00 1.0000 0.9286
Prevalence 0.35 0.3000 0.3500
Detection Rate 0.35 0.3000 0.3000
Detection Prevalence 0.35 0.3500 0.3000
Balanced Accuracy 1.00 0.9643 0.9286The model is again, convincing and highly accurate so we can repeat use predict() with model to get predictions for unknown_data, and again add it to the data
unknown_predictions <- predict(model, unknown_data, type="class")
unknown_data$predicted_group <- unknown_predictions
dplyr::glimpse(unknown_data)Rows: 75
Columns: 5
$ measure1 <dbl> 5.6, 5.0, 6.3, 6.1, 5.8, 5.5, 5.1, 5.1, 7.2, 5.0, 4.7,…
$ measure2 <dbl> 2.9, 3.6, 2.8, 2.8, 2.7, 2.6, 3.8, 3.7, 3.0, 3.0, 3.2,…
$ measure3 <dbl> 3.6, 1.4, 5.1, 4.7, 5.1, 4.4, 1.5, 1.5, 5.8, 1.6, 1.6,…
$ measure4 <dbl> 1.3, 0.2, 1.5, 1.2, 1.9, 1.2, 0.3, 0.4, 1.6, 0.2, 0.2,…
$ predicted_group <fct> B, A, C, B, C, B, A, A, C, A, A, C, A, C, B, B, C, A, …2.6.3 Random Forest with categorical predictors
In our \(k\)NN example and the previous Random Forest predictor, the input data features were solely numeric. Random Forest can handle a mixture of numeric and character or categorical based features allowing us to make classifications on more than numbers. The process is similar, so let’s get some appropriate data and do that
dplyr::glimpse(train_data_mixed)Rows: 55
Columns: 6
$ measure1 <dbl> 6.7, 5.4, 6.4, 5.0, 5.3, 5.4, 5.4, 5.7, 6.0, 5.1, 6.0, 5.8, 4…
$ measure2 <dbl> 3.1, 3.4, 3.2, 3.2, 3.7, 3.9, 3.0, 4.4, 2.9, 3.8, 2.2, 2.6, 3…
$ measure3 <dbl> 5.6, 1.7, 5.3, 1.2, 1.5, 1.7, 4.5, 1.5, 4.5, 1.9, 4.0, 4.0, 1…
$ measure4 <dbl> 2.4, 0.2, 2.3, 0.2, 0.2, 0.4, 1.5, 0.4, 1.5, 0.4, 1.0, 1.2, 0…
$ group <fct> C, A, C, A, A, A, B, A, B, A, B, B, A, A, B, C, C, A, A, B, A…
$ colour <fct> White, Green, White, Green, Green, Green, Blue, Green, Blue, …dplyr::glimpse(test_data_mixed)Rows: 20
Columns: 6
$ measure1 <dbl> 5.6, 6.7, 6.3, 6.3, 5.0, 7.2, 6.2, 6.7, 4.6, 5.1, 6.0, 6.7, 7…
$ measure2 <dbl> 3.0, 2.5, 3.3, 2.7, 2.3, 3.6, 2.2, 3.1, 3.4, 3.8, 2.2, 3.3, 3…
$ measure3 <dbl> 4.1, 5.8, 6.0, 4.9, 3.3, 6.1, 4.5, 4.7, 1.4, 1.6, 5.0, 5.7, 6…
$ measure4 <dbl> 1.3, 1.8, 2.5, 1.8, 1.0, 2.5, 1.5, 1.5, 0.3, 0.2, 1.5, 2.1, 2…
$ group <fct> B, C, C, C, B, C, B, B, A, A, C, C, C, A, A, B, A, A, B, A
$ colour <fct> Blue, White, White, White, Blue, White, Blue, Blue, Green, Gr…dplyr::glimpse(unknown_data_mixed)Rows: 75
Columns: 6
$ measure1 <dbl> 5.6, 5.0, 6.3, 6.1, 5.8, 5.5, 5.1, 5.1, 7.2, 5.0, 4.7, 7.7, 5…
$ measure2 <dbl> 2.9, 3.6, 2.8, 2.8, 2.7, 2.6, 3.8, 3.7, 3.0, 3.0, 3.2, 2.8, 3…
$ measure3 <dbl> 3.6, 1.4, 5.1, 4.7, 5.1, 4.4, 1.5, 1.5, 5.8, 1.6, 1.6, 6.7, 1…
$ measure4 <dbl> 1.3, 0.2, 1.5, 1.2, 1.9, 1.2, 0.3, 0.4, 1.6, 0.2, 0.2, 2.0, 0…
$ colour <fct> Blue, Green, White, Blue, White, Blue, Green, Green, White, G…
$ group <fct> B, A, C, B, C, B, A, A, C, A, A, C, A, C, B, B, C, A, C, B, A…We can see that there is a new categorical feature called colour in our train and test data, but not in our unknown data, so let’s try to predict the colour this time.
model2 <- randomForest(colour ~ ., data = train_data_mixed, mtry=2)
test_set_mixed_predictions <- predict(model2, test_data_mixed, type="class")
confusionMatrix(test_set_mixed_predictions, test_labels_mixed)Confusion Matrix and Statistics
Reference
Prediction Blue Green White
Blue 6 0 0
Green 0 7 0
White 0 0 7
Overall Statistics
Accuracy : 1
95% CI : (0.8316, 1)
No Information Rate : 0.35
P-Value [Acc > NIR] : 7.61e-10
Kappa : 1
Mcnemar's Test P-Value : NA
Statistics by Class:
Class: Blue Class: Green Class: White
Sensitivity 1.0 1.00 1.00
Specificity 1.0 1.00 1.00
Pos Pred Value 1.0 1.00 1.00
Neg Pred Value 1.0 1.00 1.00
Prevalence 0.3 0.35 0.35
Detection Rate 0.3 0.35 0.35
Detection Prevalence 0.3 0.35 0.35
Balanced Accuracy 1.0 1.00 1.00So we have created a model that is capable of perfectly predicting the value of the categoric value colour from a mixture of numeric and categoric features. Why is the model so accurate? It’s a bit of a fix! This sample data has a direct mapping between the group and the colour: A is always Green, B is always Blue and C is always White so it is easy to predict colour if you have group. The data aren’t typical in this sense but it does highlight the procedure.
2.6.4 Random Forest Regression
It is also possible to perform prediction of numeric values and not just classes with Random Forest. We simply set up the model with a numeric value as the predicted value in the formula as follows
model3 <- randomForest(measure1 ~ ., data = train_data_mixed, mtry=2)Now when we use predict() and omit the type argument, we get a set of numbers, not classes back
test_set_mixed_predictions_numeric <- predict(model3, test_data_mixed)
test_set_mixed_predictions_numeric 89 109 101 124 94 110 69 87
5.971972 6.240498 6.900242 6.008055 5.519931 6.887112 5.696763 6.220078
7 47 120 125 118 1 15 96
5.036305 5.179204 5.836345 6.723473 6.890082 5.087420 5.108052 5.988062
24 38 88 48
5.259467 5.011159 5.739434 4.832837 2.6.4.1 Evaluating numeric predictions
Previously we’ve evaluated predictions from our models for classes, counting True Positives etc, but we can’t do that here because we have no classes. Instead we can calculate how far away from the real value the predictions are on average. That’s a simple sum to do in R
mean( (test_data_mixed$measure1 - test_set_mixed_predictions_numeric) ^ 2)[1] 0.1747463The quantity is called the Mean Squared Error or MSE. The lower the better, though the actual size is dependent on context. The context here is the descriptive statistics of the known values for the test data, which we can get with summary()
summary(test_data_mixed$measure1) Min. 1st Qu. Median Mean 3rd Qu. Max.
4.60 5.10 5.90 5.88 6.40 7.70 These values range between 4.6 and 7.7, with 50% of them lying between 5.1 and 6.4. With that in mind it seems like an MSE of 0.17 is a pretty good result and we can conclude to predict accurately the values of measure1 from our Random Forest Regression model.
Roundup
- Supervised Learning uses labelled data to make predictions on unseen data
- Random Forest can predict classes and numeric values (perform regression)
- It is imperative to evaluate the predictive model on a set of known cases